
April 5, 2026 · 4 min read
Agentic Workflows: When AI Learns to Iterate
The shift from prompt-and-pray to autonomous task completion — how agent loops, tool use, and reflection are rewriting what language models can do.
The simplest way to use a language model is to give it a prompt and take whatever comes back. For two years, that was the paradigm — one shot, one answer, fingers crossed. But the most consequential shift in applied AI isn’t a new model architecture or a larger training run. It’s a design pattern: give the model a loop. Let it plan, act, observe the result, and try again. Andrew Ng demonstrated this in 2024 when he showed that GPT-3.5 — a model widely considered obsolete — could score 95.1% on the HumanEval coding benchmark when wrapped in an agentic workflow. GPT-4, without the loop, scored 67%. The wrapper mattered more than the model. That single result reframed the entire field. We stopped asking “which model is smartest?” and started asking “which loop is best?”
The anatomy of an agent
An agentic workflow replaces the single prompt → response call with a cycle: observe the current state, reason about what to do next, act by calling a tool (executing code, searching the web, reading a file), then evaluate whether the task is done. If not, loop. This is the ReAct pattern — Reason plus Act — introduced by Yao et al. at Princeton, and it underpins nearly every production agent today. The critical addition is tools: instead of hallucinating an answer about today’s weather, the agent calls a weather API. Instead of guessing what a function returns, it runs the code. Tool use is what separates an agent from a chatbot. It gives the model grounding in reality, and with grounding comes reliability that pure generation cannot match.
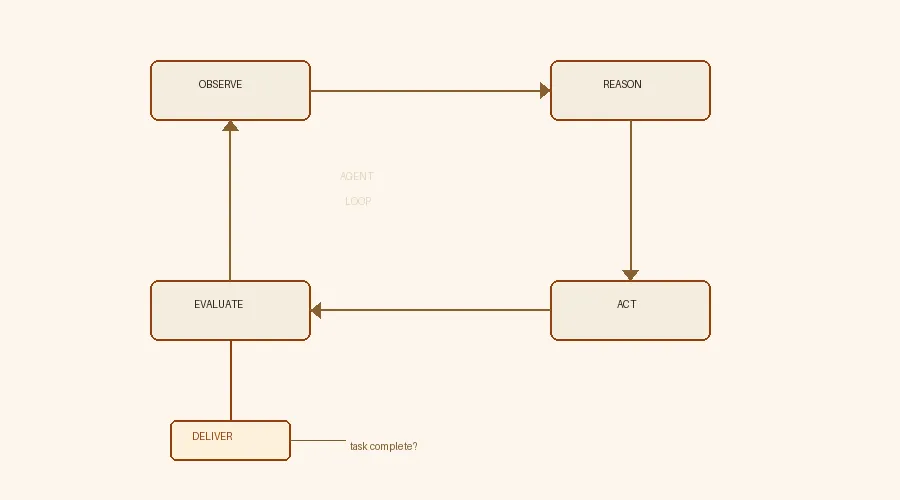
Each cycle adds information. The agent doesn’t just retry — it learns from the previous attempt. A coding agent runs tests after writing code; a research agent checks sources after drafting claims. The loop is the product.
The pattern scales in two directions. Vertically, a single agent can add reflection — evaluating its own output, critiquing its reasoning, and revising before returning a result. Horizontally, multiple specialized agents can collaborate: a researcher gathers information, a coder implements, a reviewer checks for bugs. Frameworks like LangGraph model this as a state machine with nodes and edges. CrewAI assigns agents roles and backstories. OpenAI’s Agents SDK (released March 2025) uses lightweight handoffs between agents. Anthropic’s Model Context Protocol (MCP) standardizes how agents connect to external tools — a kind of USB-C for AI integrations, adopted by thousands of community-built connectors within months of its November 2024 launch.
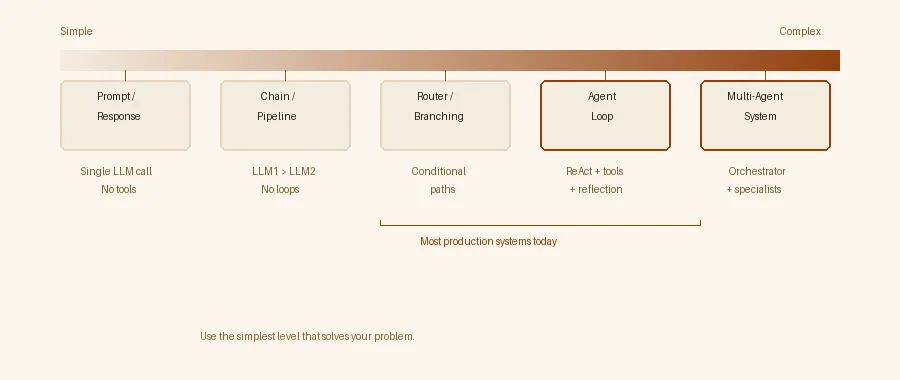
Most production systems today sit at levels 3-4. Level 5 is emerging but adds coordination overhead that rarely justifies itself unless the task genuinely requires distinct expertise.
The challenges are real and unsolved. Each step in an agent loop compounds error: at 95% accuracy per step, a 20-step task succeeds only 36% of the time. Agents hallucinate tool parameters, misinterpret outputs, and occasionally spiral into repetitive loops. Costs multiply — a complex task might require 50+ LLM calls, consuming hundreds of thousands of tokens. And autonomy introduces genuine risk: an agent with file-system access can delete your work; an agent with web access can leak data. The field is responding with sandboxing, permission models, human-in-the-loop checkpoints, and structured evaluation benchmarks like SWE-bench for coding and GAIA for multi-step reasoning.
The practical heuristic: use a single agent until it can’t hold enough context, then decompose into specialized agents — a researcher, a coder, a reviewer — each with focused tools and narrower context. More robust for complex tasks, but coordination failures become the new failure mode.
Where is this heading? Models are being trained specifically for agentic use — better tool-calling accuracy, native “thinking” modes, longer context for maintaining state across dozens of steps. Memory is moving from stateless to persistent: agents that remember past tasks, user preferences, and project context across sessions. The leading use case is software engineering — tools like Claude Code, Cursor, and GitHub Copilot Workspace have moved from autocomplete to autonomous task completion, with SWE-bench scores climbing from single digits in early 2024 to over 50% by top agents in 2025. The bitter lesson of agents echoes Rich Sutton’s original insight: scaling the loop — more tools, longer horizons, bigger context — consistently outperforms cleverer prompting on fixed-length interactions. The model is not the product. The loop is.